Abstract
3D content generation has wide applications in various fields. One of its dominant paradigms is by sparse-view reconstruction using multi-view images generated by diffusion models. However, since directly reconstructing triangle meshes from multi-view images is challenging, most methodologies opt to an implicit representation (such as NeRF) during the sparse-view reconstruction and acquire the target mesh by a post-processing extraction. However, the implicit representation takes extensive time to train and the post-extraction also leads to undesirable visual artifacts. In this paper, we propose FlexiDreamer, a novel framework that directly reconstructs high-quality meshes from multi-view generated images. We utilize an advanced gradient-based mesh optimization, namely FlexiCubes, for multi-view mesh reconstruction, which enables us to generate 3D meshes in an end-to-end manner. To address the reconstruction artifacts owing to the inconsistencies from generated images, we design a hybrid positional encoding scheme to improve the reconstruction geometry and an orientation-aware texture mapping to mitigate surface ghosting. To further enhance the results, we respectively incorporate eikonal and smooth regularizations to reduce geometric holes and surface noise. Our approach can generate high-fidelity 3D meshes in the single image-to-3D downstream task with approximately 1 minute , significantly outperforming previous methods.
Method
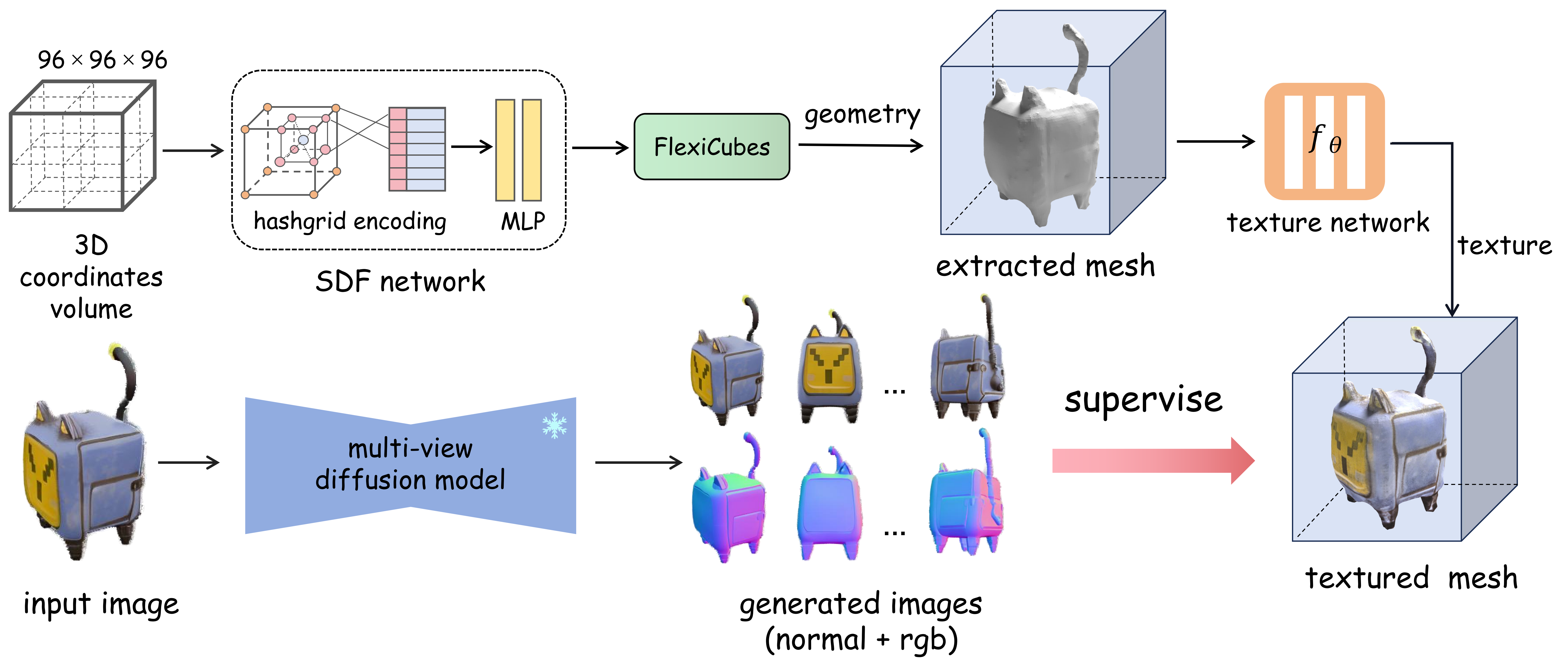
Fig. the pipeline of FlexiDreamer. The inference image is fed into multi-view diffusion model to generate multi-view images. Then an end-to-end reconstruction framework based FlexiCubes is trained end-to-end for a high-quality mesh. The mesh extracted from signed distance function can be iteratively optimized by minimizing the difference between its rendering images and multi-view generated images.
More Results